
現在、竹本研究室の学生が取り組んでいる研究について紹介しています。
研究テーマ一覧
(テーマをクリックすると該当場所へジャンプします)
- リアルタイムMRI動画からの機械学習による
発話器官の輪郭抽出及び形態分析 - リアルタイムMRIを用いたオペラ歌唱技術の検討
- 鼻副鼻腔手術による音響特性を予測する研究
- MRIから抽出した声道形状に基づくDNN多話者音声合成
- チューブ発声法が声帯振動に及ぼす影響の検討
- 調音運動のストラテジーの検討
- ポップアウトボイスの生成メカニズムに関する研究(このテーマの詳細は明記していません)
リアルタイムMRI動画からの機械学習による
発話器官の輪郭抽出及び形態分析
私たちの研究目的は、rtMRI動画から発話器官の輪郭を抽出し、人が発話する際の動きに現れる個人差などの分析を定量的に行うことです。
リアルタイムMRI(rtMRI)とは、実時間での生理学的過程を任意断面で可視化する技術であり、近年の撮像技術の急速な進歩によって発話器官各部運動の詳細の観測が可能となりました。
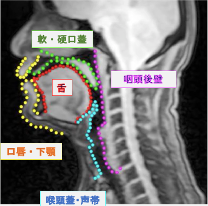
rtMRIの動画は、一本あたり数百枚の画像で構成されています。私たちはこの動画から発話器官の輪郭を抽出することで、人の発話器官の形状分析できるのではないかと考えました。しかし、一枚ずつ人の手で輪郭をなぞることは時間がかかり過ぎるため、機械学習を用いて輪郭を抽出することを考えました。これまでの研究の結果、実際の動画に使われている画像の中から数枚を人の手でなぞり、そのデータを学習させることで他の動画から自動で輪郭を抽出することができるようになりました。現段階では、10名の動画から機械学習を用いた輪郭抽出が可能となっています。この輪郭を用いて、後述の形態分析を行っています。
人の発話運動には個人差が存在します。その差を反映した調音運動によって男女差の声の高低や個人間の声色の違いが生じていると考えられていますが、その個人差が実際にどの部分にどれだけ生じているのかを定量的に分析した研究は今現在ではなされていません。本研究では点群として輪郭を抽出しています。全フレームで発話器官ごとに始点と終点は解剖学的に相同であり、輪郭を構成する点数は共通であるため、フレーム、部位ごとに点群を等間隔に再配置することで、異なる話者間での定量的な分析が可能となります。
現段階までは、18名分の輪郭を用いて平均的な形状を生成し、主成分分析により個人差がどの発話器官にどのような動きで現れているかを分析したり、対応する点と点の距離の平均から、/maka/のような子音と母音がつながっている発話において、/m/と/k/の前後どちらの子音が間の母音/a/の影響を強く受けているのかを分析しており、母音発話の平均的な動きと個人差を含んだ動きを明らかにすることができました。
研究実績はこちら(クリックしてください)
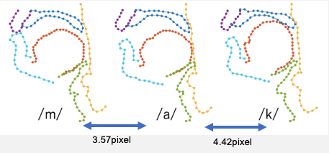
(/m/と/a/の間は3.57pixel,/k/と/a/の間は4.42pixelの平均距離があり,/k/よりも/m/の影響が強いと判断した)
リアルタイムMRIを用いたオペラ歌唱技術の検討
オペラ歌唱とは、歌唱を中心に物語を展開する舞台芸術です。ソプラノ、メゾソプラノ、アルト、テノール、バリトン、バスの6つの声種が存在し、拡声機器がなくてもオーケストラにマスクされない響く声や、大きな声量、特徴的な音色を持つ歌声などが特徴です。
この歌声には、歌い手のフォルマント(Singer’s Formant)などの特有の音響的特徴が見られます。これを実現するためには訓練が必要ですが、この訓練によって発話器官の制御がどのように変化したかは明らかになっていません。
そのような中、近年リアルタイムMRIと呼ばれる技術が発達してきました。これは磁気共鳴画像法(MRI)を用いてリアルタイムで体内運動を撮像する技術のことです。この技術を用いることで、歌唱をしているときの発話器官の運動を観測することが可能となりました。
そこで本研究ではリアルタイムMRIを用いて、オペラ歌唱の技術にはどのような発話器官の制御が必要なのか解明することを目的とし、研究を行っています。
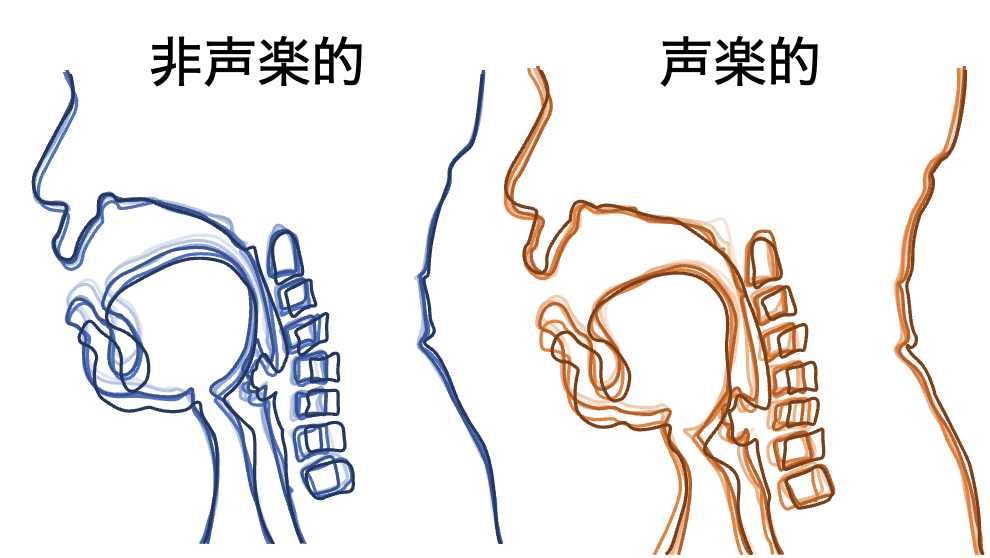
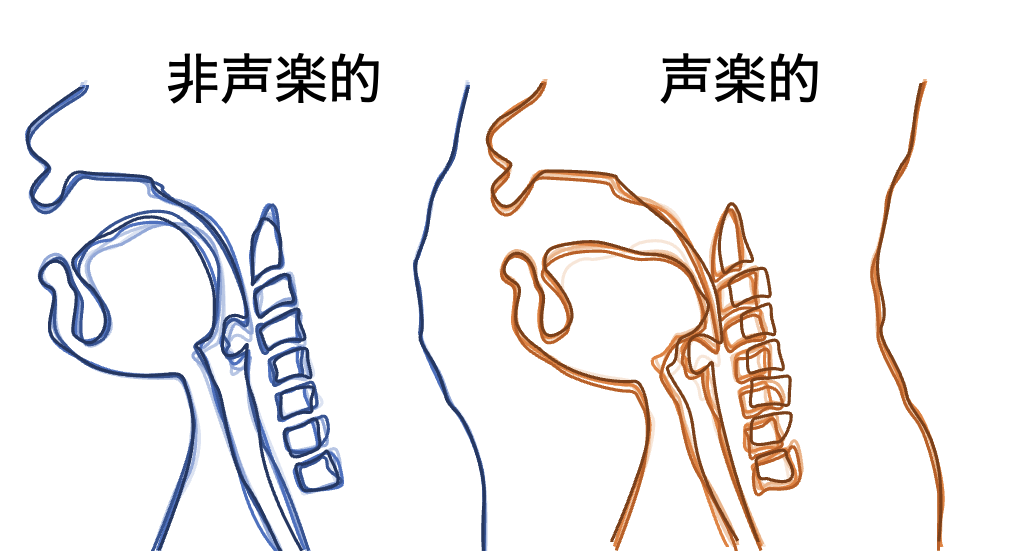
これまでには、歌唱中に歌い手のフォルマントが見られたプロのオペラ歌手と、歌い手のフォルマントが見られなかった、声楽を学ぶ学生に、それぞれ熟達した歌唱法を用いた発声(声楽的な発声)とその歌唱法を用いずに発声(非声楽的な発声)をしていただき、そのときの横隔膜や声道の形状をリアルタイムMRIで観測しました。その結果、プロは、歌いだしの吸気による横隔膜の下降具合が、声楽的な発声と非声楽的な発声で異なっており、歌い手のフォルマントの生成に重要とされる喉頭の位置も、声楽的な発声では非声楽的な発声よりも大きく下がっていました。学生は横隔膜の下降具合は発声方法によって違いはなく、喉頭の位置も大きくは異なりませんでした。そして、オペラ歌唱では、地声と裏声などの2つの声区を融合させて、音色や声の厚みを一定に保つ技術が重要ですが、この技術には頸椎を連続的に後弯させることが関係している可能性も明らかになりました。
またこの結果以外にも、訓練を重ねたオペラ歌手は、高音から低音へ移行する際に「支え直す」技術を用いていますが、このとき肺の容積を一時的に増大させることで肺圧を下げていることなども明らかになりました。
研究実績はこちら(クリックしてください)

鼻副鼻腔手術による音響特性を予測する研究
声帯から出た音源が咽頭を通り、鼻腔・副鼻腔(前頭洞、篩骨洞、上顎洞、蝶形骨洞)を通って鼻孔から放射されることで、鼻音を発声します。鼻腔・副鼻腔は複雑な形状をしており、個人差が大きいため、音声の個人性の重要な生成要因であると言われています。そのため、鼻副鼻腔の手術によって、音声の個人性が変化しますが、今のところ術前にその変化を予測する術はありません。
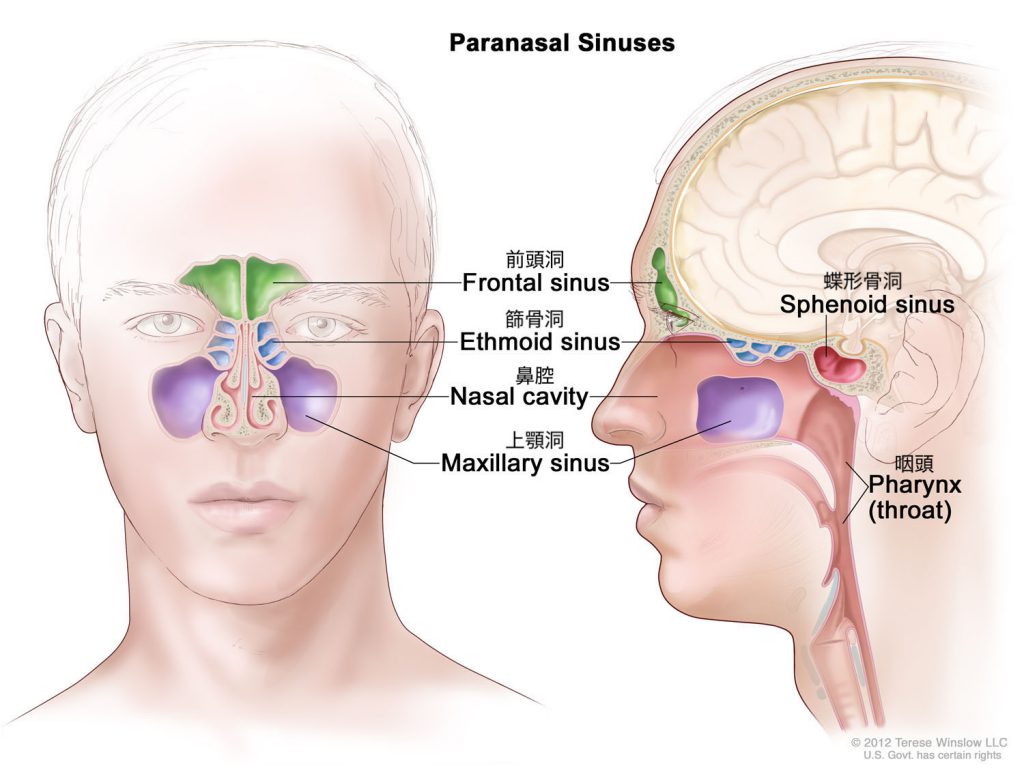
(引用:Terese Winslow LLC, Medical And Scientific Illustration, Head And Neck, https://www.teresewinslow.com/#/head/)
そこで我々は、鼻副鼻腔の形状と録音データから、手術による音声変化を術前にシミュレーションで予測できるシステムの構築を目的とし、研究を行なっています。
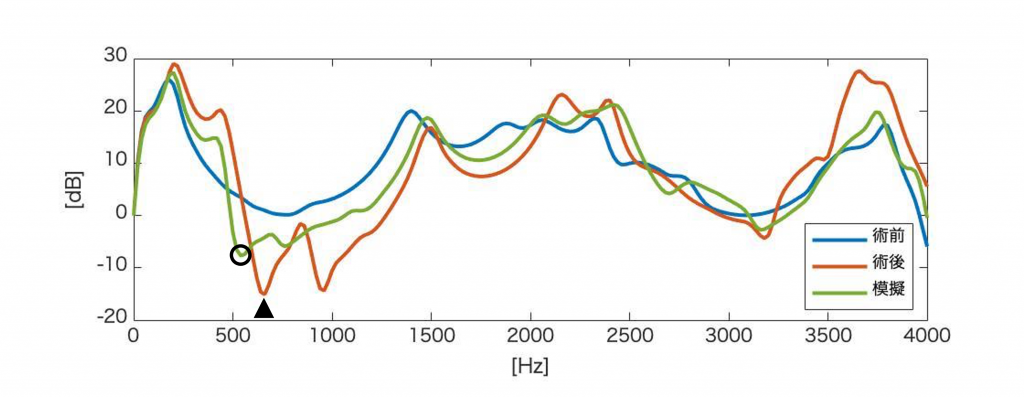
それに伴い、収集された被験者のCTデータを用いて音響シミュレーションの方法を確立しました。それ用いて、内視鏡下鼻副鼻腔手術を受けた患者の術前・術後の形状と音響特性の変化を調べました。その結果、手術によって篩骨洞が開放されたことで、ディップ周波数とディップ生成に関与する分岐管の組み合わせが変化し、中でも前頭洞と上顎洞が音響的に一体化する傾向が強くなることがわかりました。また、患者の術後のCTデータを参考にしながら、術前のCTデータで模擬手術を実施し、音響シミュレーションを行うことで、手術による形状変化が伝達関数に及ぼす影響を検討しました。その結果、模擬手術によって、術後の伝達関数を再現することが可能であることが判明しました。
この過程で、実音声から計算されたスペクトルと音響シミュレーションによって計算された伝達関数が一致しないという問題が生じ、検討したところ、鼻周期や首の角度が変化することが要因であると判明しました。また、鼻音発声時の副鼻腔およびその他の分岐管が生成するディップの成因についても検討しました。その結果、手術によって自然口が開放されたことで、副鼻腔同士が音響的に一体化する場合が増加すること、また、1000Hz付近に生じるディップが口腔に由来するものであることもわかりました。
研究実績はこちら(クリックしてください)
MRIから抽出した声道形状に基づくDNN多話者音声合成
近年の音声合成では、DNN(Deep Neural Network)を用いた手法により、従来の音声合成手法と比較して自然音声と同等の評価が得られるほど精度が向上しています。また、たくさんの音声の学習データから任意の話者を再現する音声合成(DNN多話者音声合成)も検討されています。話者の情報をベクトルで表している、話者埋め込みベクトルを用いて学習する手法が広く用いられていますが、既存手法だとベクトルの数値が声のどの特徴を表しているか不明であるため、パラメータを制御することが困難でした。そこで、声の高さやフォルマントなどの明示的な音響特徴量を用いて学習することで、ベクトルの数値が声のどの特徴を表しているか分かりやすく、精度も既存手法と同程度の手法が提案されました。
先ほどまでの課題では音響特徴量を音声から抽出していましたが、音響特徴量は話者の発話器官(声帯、口腔など)の形態に由来することから、本研究では、MRIデータの画像から音響特徴量を抽出して学習した場合でも同程度の類似度が得られるのか検討します。MRIデータから音響特徴量を抽出する方法として、フォルマントは声道形状から声道断面積関数(声道の断面積の変化を表した関数)から声道伝達関数のピークをとることで抽出でき、声の高さはF0(基本周波数)を予測するCNNモデルを用いて抽出しています。
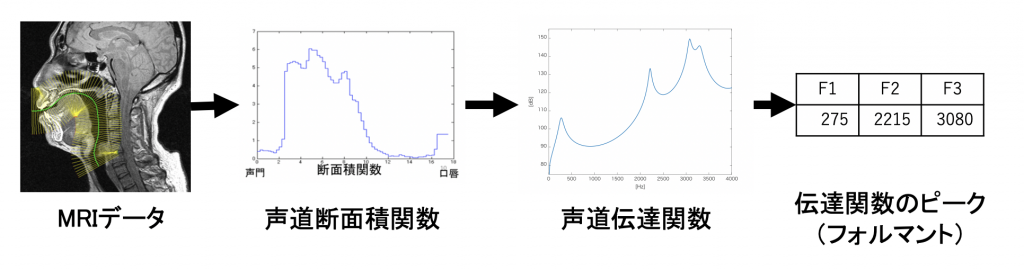
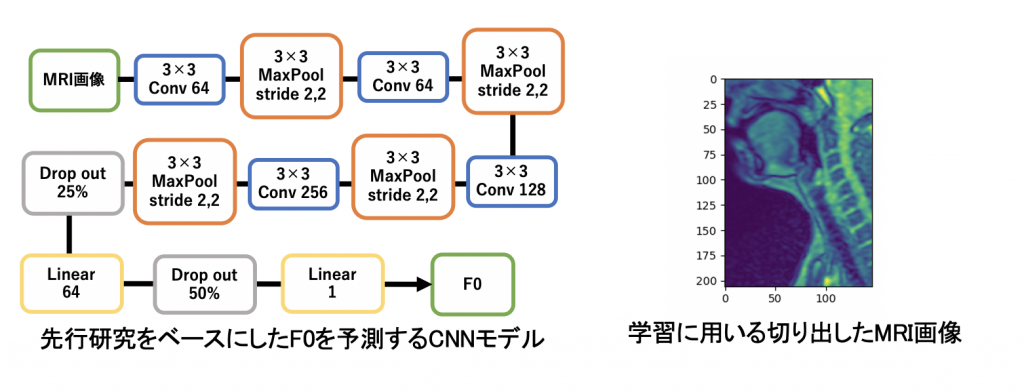
精度は音声から抽出した時の精度よりも劣っていました。原因として、MRIでは仰向けになって撮像するため、舌の位置が通常発話時と異なる位置に来るため、フォルマントが変わってしまったことが挙げられます。現在はこの原因の改善や他の原因がないか確認し、精度の改善を検討しています。最終的な研究の目標としては、MRIデータのみからその話者の声の再現を目標としています。
また、今年度からテキストから声道形状の予測をする研究も開始しています。
研究実績はこちら(クリックしてください)
チューブ発声法が声帯振動に及ぼす影響の検討

チューブ発声法の訓練姿
チューブ発声法とはチューブ(ストロー)を用いる音声訓練技法の1つです。主に発声に問題のある患者の治療や声楽のウォーミングアップなど、広く用いられています。チューブ発声法は図のようにチューブを加えて発声を行う訓練になります。
チューブ発声法の訓練の効果に、基本周波数の最高値の上昇(声が高くなる)、声帯振幅の増加(声が大きくなる)が挙げられています。またI. R. Titzeらによるコンピューターシュミレーションで、理論的にチューブ発声法の効果が示されています。チューブ発声法は声帯を傷めずに効率よく発声できるという効果が示されています。 現在、チューブ発声法の訓練を継続的に行なった人は基本周波数の最高値が上昇することが分かっています。しかし、その上昇率にはばらつきがありどの程度の期間で効果が出始め、訓練の効果はどの程度持続するのかということが十分に検討されていません。また、どのようなチューブの形状だと効率が良く訓練を行うことができるか分かっていません。今後はシュミレーションにてチューブの形状を検討しつつ、実験参加者を募り実際に訓練を行う予定です。
調音運動のストラテジーの検討

声道断面モデル
(引用:音声音響研究所,声紋とは?,
http://www.onkyo-lab.com/voiceprint.html)
肺から押し出される空気によって声帯を振動させ、「三角間隙鋸歯状波」というブザーのような「声帯の基本振動音」が作られます。この声帯の基本振動音が、頬骨、上顎骨、下顎骨等によって構成される口腔、鼻腔等の声道を通過する際に声道で共鳴したものが、口や鼻から外部に放射されることによって、我々の耳に達する「声」になります。
人の声の生成過程における、舌や口唇などの調音器官の運動は調音運動と呼ばれています。調音運動によって音声の音響特性(声の高さや響きなど)が変化し、それが音韻性として知覚されています。つまり、調音運動は、音声に言語的情報を付加する役割を持っています。また、調音運動が行われる口腔内のことを調音空間と呼びます。
本研究では、人が話す速さを変える時の調音運動の変化について調査します。また、人が話す速さを変化させるためにその都度調音運動を変化させることを調音運動のストラテジーと呼び、どのような調音運動のストラテジーがあるのかということを検討していきます。
