
現在、竹本研究室の学生が取り組んでいる研究について紹介しています。
研究テーマ一覧
テーマをクリックすると該当場所へジャンプします。
参考文献は各テーマごとに番号を振っておりますのでご注意ください。
- 機械学習を用いたリアルタイムMRI動画からの
発話器官の輪郭抽出及び形態分析 - 統計的分析に基づくオペラやポップスなどの歌唱技術の研究
- 模擬手術と音響シミュレーションに基づく鼻副鼻腔の音響特性の解明
- リアルタイムMRIから抽出した声道形状を介した音声合成手法の研究
- Waveを用いた滑舌や言い間違いにおける調音運動の研究
- ポップアウトボイス生成のメカニズムに関する検討
機械学習を用いたリアルタイムMRI動画からの
発話器官の輪郭抽出及び形態分析
近年、磁気共鳴画像法(MRI)による撮像技術が進歩し、体内の任意断面を高速で撮像することによって、発話中などの体内運動を観測することができる、リアルタイムMRI(rtMRI)という技術が発達してきました。そこで私たちは、日本語調音音声学の精緻化のために国立国語研究所と共同で「リアルタイムMRI調音データベース(rtMRIDB)」を構築しました[1]。このデータベースには25名の実験参加者による、様々な発話を記録した動画が収録されています。
調音音声学の研究はこれまで、実験参加者の主観報告に基づいて行われてきました[2]。しかし、精緻化のためには定量的に分析することが不可欠です。そこで私たちは、rtMRIで撮像した全ての画像から発話器官の輪郭を点群で抽出しています。全ての画像から手動で輪郭を抽出するのは、膨大な手間と時間がかかるため、機械学習ライブラリDlib[3]を用いて半自動的に輪郭を抽出する技術を確立しました。この技術によって抽出した輪郭データは、現在データベースで公開されています。
また、rtMRI動画への歯列補填にも取り組んでいます。MRIでは歯列と口腔が同じ輝度値で撮像されるため、歯列を目視で判別できません。このことは、日本語の「サ行」や「タ行」のような歯列に舌を接近させたり、接触させたりする際の発話器官分析で大きな課題となっていました。そこで私たちは、rtMRI動画で撮像した全ての画像から歯列が舌や口唇で囲まれて形状がわかる画像を取り出して歯列データを作成し、画像の位置合わせによる手法で歯列の位置を推定し、rtMRI動画に歯列を補填することに成功しました。これらの技術を用いて、私たちは発話器官の形態分析を行っています。
形態分析では、拗音の生成メカニズムの解明に取り組んでいます。拗音とは「きゃ」のようにイ段の仮名に小さいヤ行の文字を加えて表すモーラ(日本語音声における韻律の基本単位)であり、「か」のように仮名1文字で表す直音と対立します。日本語の構造は、「あ」「い」「う」などの単母音と、促音(「っ」)などの特殊拍を除いて、基本的に1個の子音と1個の母音で構成されています。一方で、拗音はこの基本構造とは異なります。拗音の構造については様々な説がありますが、口や舌、軟口蓋などの調音器官の運動の側面からは分析されておらず、どのような構造になっているのか未だ明らかになっていません[4]。そこで11人の話者のrtMRI動画を用いて、サ行とカ行の直音と拗音を主成分分析し、子音から母音への調音器官の変化パタンを分析しました。その結果、拗音の頭子音は硬口蓋化していること、わたり音/j/が生成されてから母音が生成されていることを示唆する結果が得られました。すなわち、拗音は「口蓋化した子音」「わたり音」「母音」という3つの要素から構成される、例外的な拍である可能性が示されました。
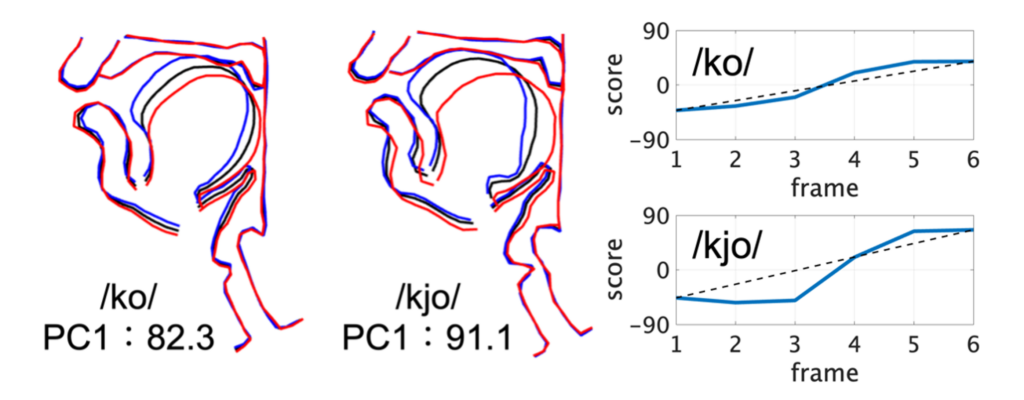
(左2つの図は、数値が寄与率、青が子音、黒が平均、赤が母音を示す。
右図は、青の実線がPC1、破線がPC1を結んだ直線を示す。)
- K. Maekawa, “Real-time MRI articulatory movement database and its application to articulatory phonetics”, Acoust. Sci. & Tech., Vol. 46, No. 1, pp. 45-54 (2025).
- 本多清志, “-母音研究: Chiba & Kajiyama から最新研究まで- 母音生成研究と観測技術の進展“, 音響学会誌 58巻 7号, pp. 420-425 (2002).
- D. E. King,“Dlib-ml: A Machine Learning Toolkit”, Mach. Learn. Res., Vol. 10, pp. 1755-1758 (2009).
- A. Nogita, “Arguments that Japanese [Cj]s are complex onsets: durations of Japanese [Cj]s and Russian [Cj]s and blocking of Japanese vowel devoicing”, Working Papers of the Linguistics Circle, Vol. 26, No. 1, pp. 73-99 (2016).
統計的分析に基づくオペラやポップスなどの歌唱技術の研究
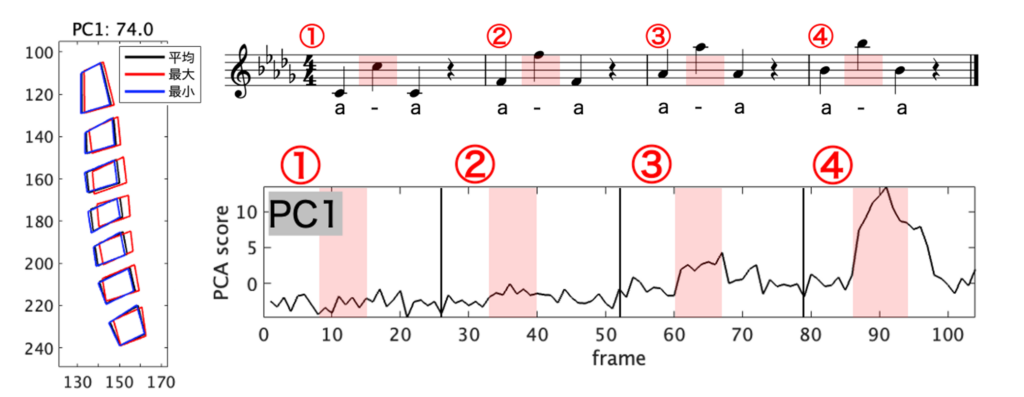
優れたオペラ歌手は、豊かな声量や特有の響きのある声質、力強い高音などを有しています[1]。これらはオペラ歌手が「歌い手のフォルマント(Singer’s Formant)」と呼ばれる、人の耳に聞き取りやすく、楽器音とは異なる周波数帯域に声道の共鳴周波数のピークを生成する技術など、さまざまな技術を長い訓練によって習得することで、実現されています[1]。しかしこの訓練によって、オペラで重要とされる声道形状や横隔膜の制御がどのように変化したのかは明らかではありません。そこで我々はリアルタイムMRIと呼ばれる、リアルタイムで体内運動を任意断面で観測することができる技術[2]や、声道の3次元形状をMRIで撮像することで、これらの技術を解明することに取り組んでいます。
リアルタイムMRI撮像では、声道と肺の形状をそれぞれ撮像し、機械学習を用いて点群でそれぞれの輪郭を全ての動画のフレームから抽出しました。そしてこの点群を等間隔に再配置し、主成分分析を行いました。その結果、音高の上昇に伴ってオペラ歌手は頸椎を後弯させることが明らかとなりました。頸椎の後弯を利用した新たな音高調節の機構を用いている可能性が考えられ、これはオペラ歌手が高音でも、薄い声質にならずに発声できる[3]要因のひとつかもしれません。肺の形状の分析からは、歌手が「支え直す」技術を用いる高音から低音に移行した際に、横隔膜の背側を動かして肺の容積を増大させることが明らかとなりました。また肺圧を圧縮性の流体として推定した結果、この動きによって肺圧を減少させていることが明らかとなりました。先行研究により、高音では高い肺圧が、低音では低い肺圧が必要[4]なことが明らかとなっていることから、「支え直す」と呼ばれる技術は、横隔膜の背側を動かすことで音高に適した肺圧に制御する技術であることが考えられます。
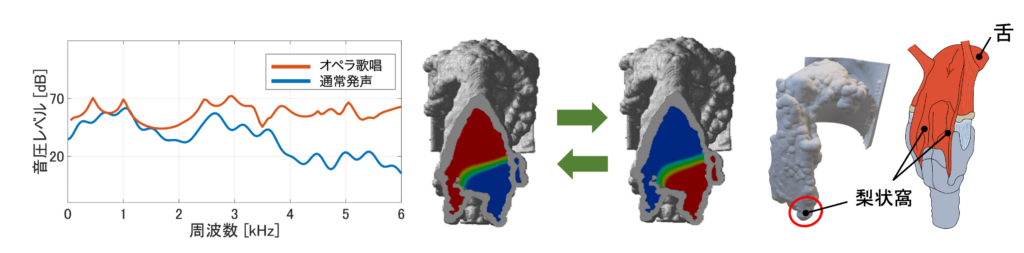
MRIを用いた声道の3次元形状の撮像では、撮像したデータから「声道模型」と呼ばれる人間の声の通り道(声道)をコンピュータ上で再現したモデルを用いて分析を行い、歌い手のフォルマントの生成メカニズムを明らかにする研究に取り組んでいます。声道模型を用いて音響シミュレーションを行うと、声道の音響的な特徴を示す「声道伝達関数」と、声道のどの部位が重要であるかを確認できる「瞬時音圧分布」を得ることができます。この2つのデータから分析を行った結果、「梨状窩」と呼ばれる喉付近に存在する袋状の部位が歌い手のフォルマントの生成に重要であることが明らかとなりました。現在、この結果の声種差や母音差について検討を行っています。
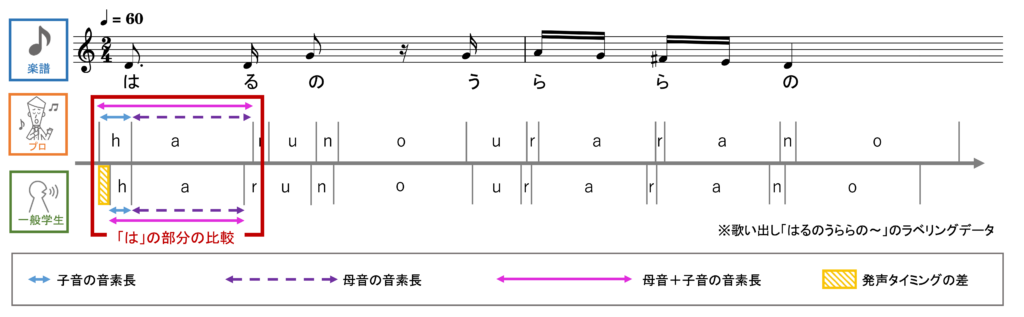
また、オペラ歌唱の子音の発声技術に着目した研究も行っています。プロのオペラ歌手は,聴衆に歌詞を明瞭に伝えることができます。歌詞は母音と子音から成り立っており,明瞭に伝えるためには子音にも高度な発声技術があると考えられます。しかし,従来のオペラ歌唱の研究では,音響的なパワーの大きい母音の発声技術に関する研究が中心で[1],子音の発声技術に関する研究は少数です。そこで、本研究では子音に着目して研究を行っています。これまでに、プロのオペラ歌手(プロ)と一般学生(学生)に武島羽衣作詞・滝廉太郎作曲の「花」を歌唱してもらい、その音声を分析して音素の継続時間長(音素長)や各音素に対して楽譜で指示された発声開始時刻と実際の発声開始時刻の差(発声タイミング)の分析を行いました。その結果、音素長については、プロは語頭の子音を学生よりも有意に長く歌唱していることが明らかになりました。また、プロは破裂音の前に存在する閉鎖区間が有意に短く、無声破裂音では気音部、有声破裂音では母音への過渡部を長く発声していました。これは、歌声が閉鎖区間によって途切れないようにしている可能性があります。発声タイミングについては小楽節の頭の部分で早くなっており、それによって歌詞を印象付け明瞭に聞こえるようにしている可能性が考えられます。現在は、この研究を元に子音と母音の音素長の変化や音高が歌のうまさに与える影響についての研究を行っています。
さらに今後は、オペラだけではなく、ポップスなど様々なジャンルにおける歌のうまさについての研究も行っていく予定です。
- J. Sundberg, The Science of the Singing Voice, Northern Illinois University Press, DeKalb, 1987.
- O. Engwall, “A Revisit to the Application of MRI to the Analysis of Speech Production-Testing our assumptions,” Proc. 6th Int. Semin. Speech Production, pp. 7–10, 2003.
- コーネリウス・L・リード (訳: 渡部東吾), ベル・カント唱法ーその原理と理論, 音楽之友社, 東京, 1987.
- Cleveland & Sundberg, “Acoustic analysis of three male voices of different quality,” Proc. SMAC83, no.1, pp.143-156, 1983.
模擬手術と音響シミュレーションに基づく
鼻副鼻腔の音響特性の解明
声帯振動は、喉頭や咽頭を通り口腔、鼻腔へ分岐し体外へ放出されます。この際、舌や口蓋などを動かし口腔の形状を変形させることで、「た」「け」「も」「と」等の言葉を発しています。一方、鼻腔や副鼻腔は骨と粘膜で形成されているので、その形状を動かすことができません。さらに、鼻副鼻腔は非常に複雑な形状をしており、個人差があります[1]。そのため、音声の個人性を生成する要因の一つであると言われています[2,3]。この鼻腔・副鼻腔を手術によって変形させてしまうと、音声の個人性が変化する可能性がありますが、その変化を予測する術はこれまでありませんでした。
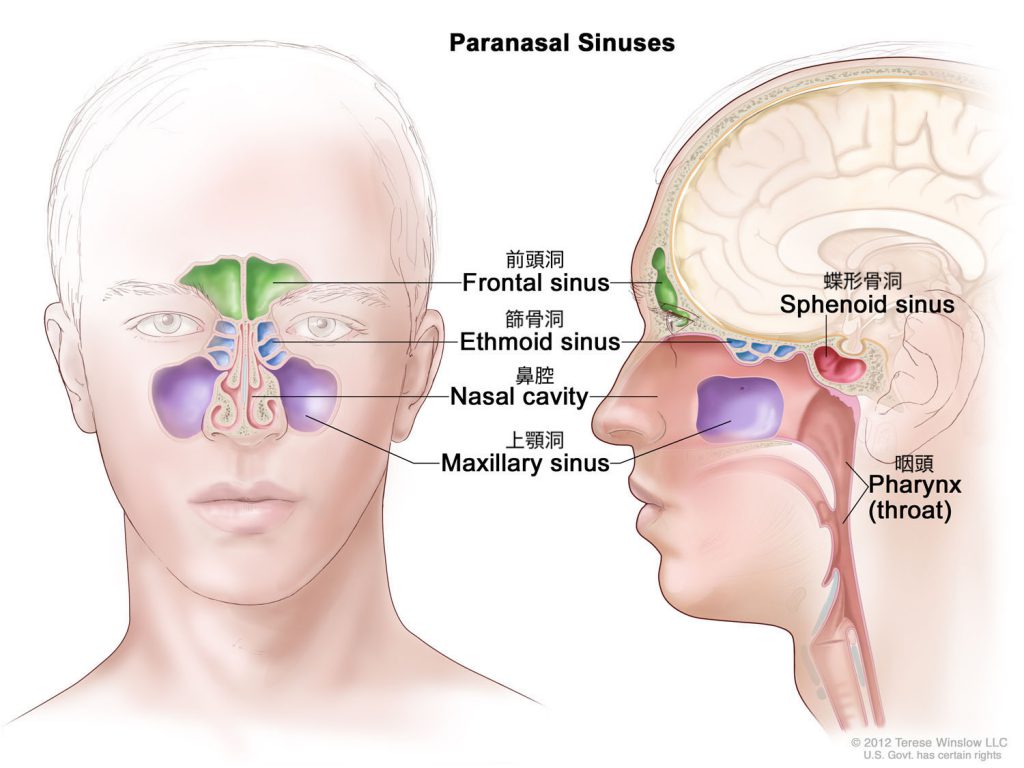
そこで、本研究室では鼻副鼻腔に関する研究として音響シミュレータの構築と模擬手術と音響シミュレーションによる音響特性の解明に取り組んでいます。最終的には、鼻副鼻腔手術を受ける患者に対してインフォームドコンセントとして手術後の音声変化の情報を提供することを目標としています。
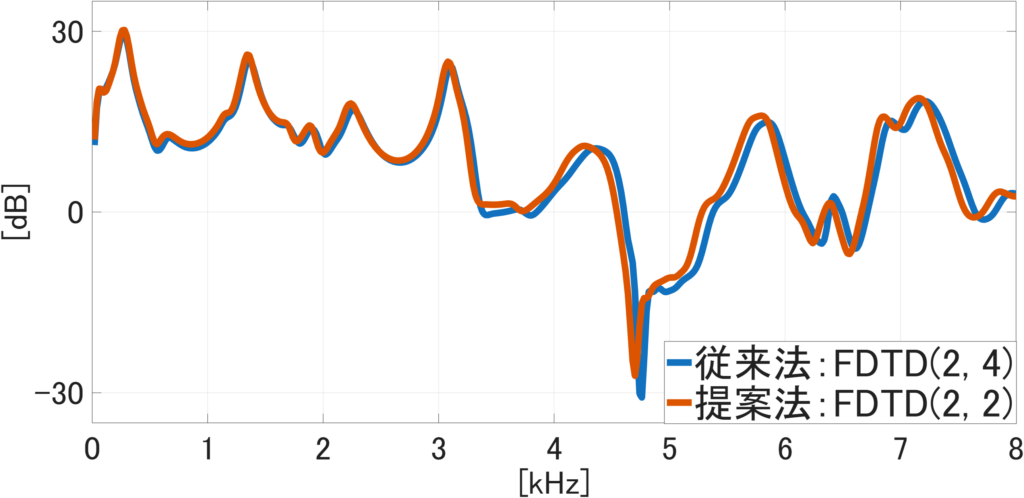
音響シミュレータの構築について、高速化による計算時間の短縮に取り組んでいます。本研究室の音響シミュレータではFDTD(Finite-Difference Time-Domain)法を用いて音波の伝搬を計算しており、3次元の鼻副鼻腔形状の音響特性を計算するには膨大な要素数の計算が必要です。特に高精度に音響特性を計算するFDTD(2, 4)法ではより膨大な計算コストを要します。従来ではMPI(Message Passing Interface)を用いた複数のCPUによる並列計算によって高速計算を行っていましたが、1回の音響特性の計算に1時間以上要しています。そこで、2023年度より高速計算が可能な音響シミュレータの構築に着手しました。このシミュレータではGPGPU(General-Purpose computing on Graphics Processing Units)を用いた並列計算と従来よりも計算コストが低いFDTD(2, 2)法を採用しました。その結果、従来では1時間以上要する計算を最短で1分37秒まで短縮することができました。また、計算精度については従来法と比較して若干の低下が認められましたが、聴感上の差はありませんでした。計算結果の提示方法として音響シミュレータでは、音響特性の他に空間内の音の広がりを可視化できる音圧分布を出力することができます。音圧分布を計算・出力するために、従来では9時間以上要していましたが13分43秒まで短縮することができました。今後は、更なる高速化と利便性向上による実用化を目指します。

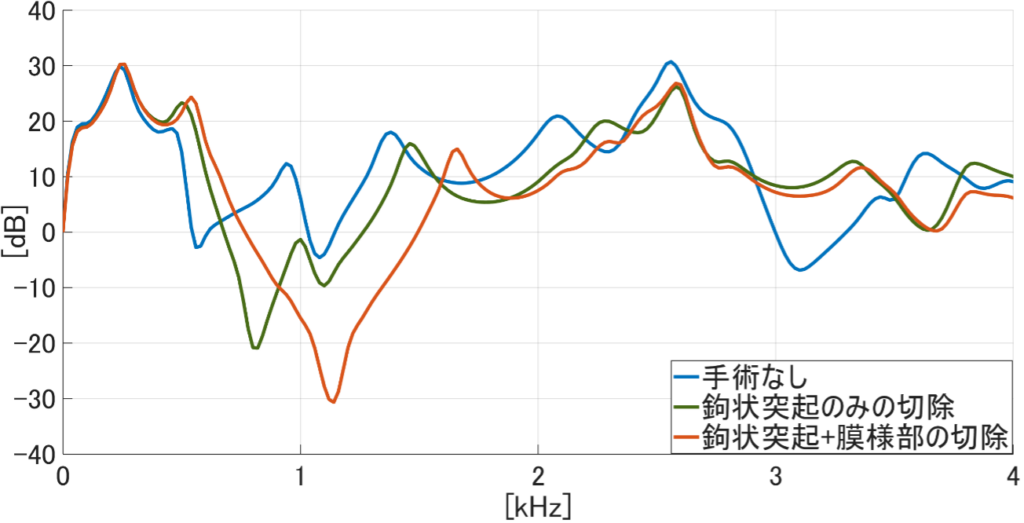
模擬手術と音響シミュレーションによる鼻副鼻腔の音響特性の解明について、現在は副鼻腔の部位の1つである上顎洞の開放範囲(切除規模)の違いによる音声変化への影響の検討に取り組んでいます。本研究室では患者のCT(Computed Tomography)データから鼻副鼻腔を含めた声道形状を抽出し、抽出したデータを用いて手術(模擬手術)を行います。そのデータに対して音響シミュレーションを用いることで、手術後の音声変化を予測する手法を確立しました。この手法の確立によって実際に実験を行うことが難しい、開放範囲の違いによる音声変化の違いを検討することが可能となりました。
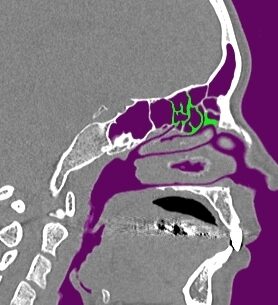
(緑:模擬手術による切除範囲)
そこで現在は、2024年度の研究にて副鼻腔のうち特に音声変化への影響が大きいことが示された上顎洞の開放範囲による音声変化について検討をしました。上顎洞の開放範囲は鉤状突起と膜様部の切除規模によって決まります。鉤状突起とは骨の突出部のことであり、膜様部は鉤状突起と接続している薄い粘膜のことです。これらの部位の切除によって副鼻腔の容積が拡大します。検討の結果として、上顎洞の開放範囲が小さい程音声変化が小さく、範囲が大きい程音声変化が大きくなる可能性が示唆されました。しかし、被験者によっては開放範囲が小さいのにも関わらず音声変化が大きくなる傾向も見られました。
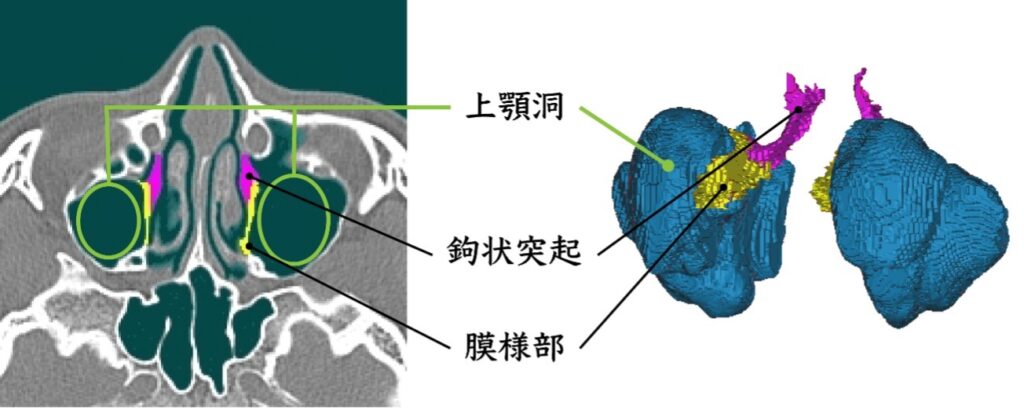
- Dang et al., “Morphological and acoustical analysis of the nasal and the paranasal cavities”, JASA., 96(4), 2088-2100, 1994.
- Amino et al., “Idiosyncrasy of nasal sounds in human speaker identification and their acoustic properties”, Acoust. Sci. Tech., 27(4), 233-235, 2006.
- Amino et al., “Effects of stimulus contents and speaker familiarity on perceptual speaker identification”, Acoust. Sci. Tech., 28(2), 128-130, 2007.
- Terese Winslow LLC, Medical And Scientific Illustration, Head And Neck, https://www.teresewinslow.com/#/head/ (閲覧日:2025/09/16)
リアルタイムMRIから抽出した声道形状を介した
音声合成手法の研究
音声合成とは、機械で人工的に音声を作り出す技術です。近年では、DNN(Deep Neural Network)という技術を用いて、大量のテキストと音声の組み合わせを学習することで、より自然な音声を再現できるようになりました[1]。また、複数の話者のテキストと音声を用いて、テキストと音声の対応関係の他にそれぞれの話者の個人性を学習し、学習に用いていない話者の音声を再現する「多話者音声合成技術」の研究が進められています[2,3]。この研究では、話者の声の特徴を数値ベクトルで表す、話者埋め込みベクトルを用いて学習する手法が広く用いられています。しかし、話者埋め込みベクトルは音声データから生成するため、病気などで声を失った人の音声を再現することはできません。
そこで、私たちは人が発声する際の音声の生成過程に着目しています。人の音声は、肺から出た空気が声帯を振動させて音を作り、その音が声道を通ることで、言語的な特徴が付与されます。声道は、口や舌、軟口蓋などの調音器官によって構成され、これらの器官を動かすことを「調音運動」といいます。この調音運動によって声道の形状が変化し、音声が決まるため、声道形状を用いることでその話者の音声を再現する技術の実現を目指しています。
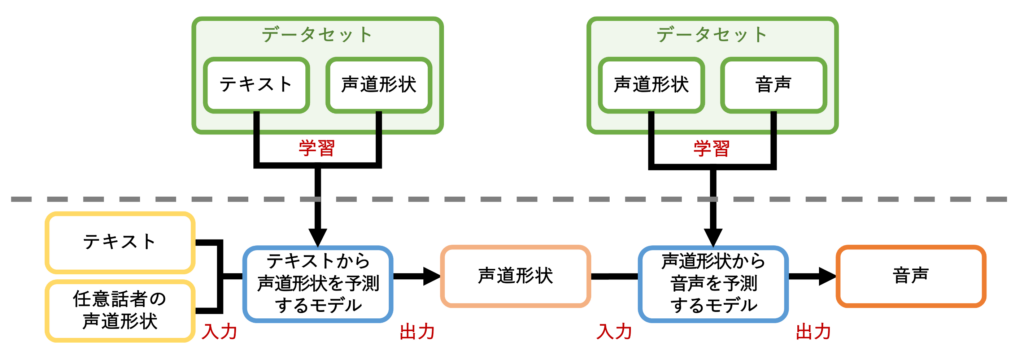
現在は1名の話者のデータを用いて、テキストから声道形状を予測するモデルおよび声道形状から音声を予測するモデルを構築しています。さらに、両モデルを統合したテキスト音声合成モデルを構築し、精度を検証しています。今後は、複数話者のデータを用いて学習を行い、話者の個人性が再現されるかを検討していきます。
(黄:正解、赤:予測結果)
また、声道形状を介した音声合成の研究の一環として、音声と調音との関連を解明することを目的とし、音声の生成過程とは逆に音声から調音運動を推定する「音声-調音マッピング」という研究も行っています。これはAcoustic to Articulatory Inversion(AAI)として知られ、音声合成に限らず、音声認識や言語学習、発話治療など様々な分野への応用が期待されています。従来のこの研究で調音運動の観測に多く用いられていた、舌や口唇にセンサを貼り付けてセンサの位置を記録し、調音運動を観測するEMA(Electro Magnetic Articulography)とは異なり、本研究ではリアルタイムで任意断面の体内運動を観測することができる、リアルタイムMRI(rtMRI)を用いることで、調音器官全体の位置や形状を観測しています。
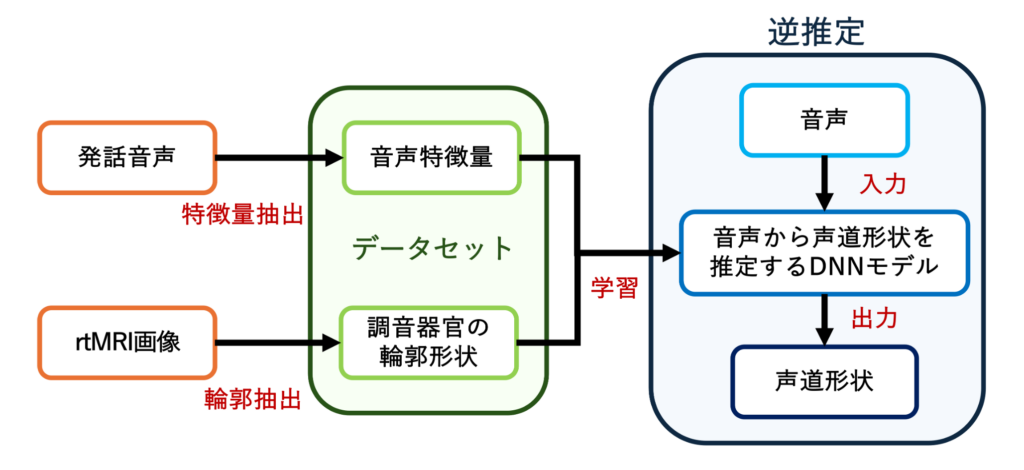
(赤:輪郭抽出による正解の輪郭、青:推定した輪郭)
推定精度に関して、現状では誤差が約1 pixelですが、音素環境によっては誤差の大きいフレームも存在しています。フレームによって精度が低下する原因のひとつとして、この逆問題には音声に対して調音が非一意性を有する可能性が挙げられます。
各調音器官の位置や形状が同一な状態に対して音声は一意に生成されます。一方で、同一とみなすことのできる音声を生成可能な調音器官の状態は多数存在すると考えられています。そこで我々は現在、日本語通常発話の母音と一部の子音について、クラスタリング等を用いて音声-調音マッピングの逆問題における非一意性について基礎的な検討を行っています。その結果、どの音素も非一意性を有するものの、一部音素においては一意に近い傾向も確認しています。
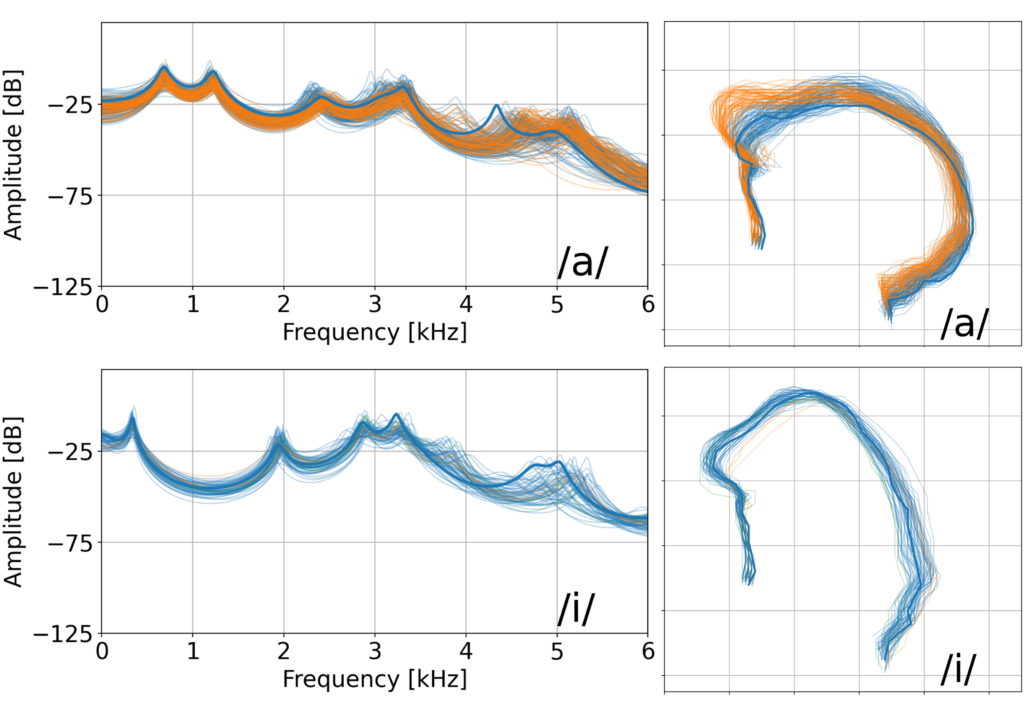
(舌輪郭形状の分類されたクラスタに基づき色分け)
- 全炳河, “テキスト音声合成技術の変遷と最先端”, 日本音響学会誌, vol. 74, no.7, pp. 387-393, 2018.
- Arik et al., “Deep Voice 2: Multi-Speaker Neural Text-to-Speech”, Proc. NIPS, pp. 2966-2974, 2017.
- Hojo et al., “DNN-Based Speech Synthesis Using Speaker Codes”, IEICE TRANS. INF. & SYST., vol.E101–D, no.2, pp.462-472, Feb. 2018.
- Mitra et al., “Hybrid convolutional neural networks for articulatory and acoustic spaces”, Speech Communication, vol. 89, pp. 103-112, 2017
- G. Fant, Acoustic Theory of Speech Production, Mouton, 1960.
- Qin & Carreira-Perpiñán, “An Empirical Investigation of the Nonuniqueness in the Acoustic-to-Articulatory Mapping”, Proc. Interspeech, pp. 74-77, 2007.
Waveを用いた滑舌や言い間違いにおける調音運動の研究
本研究では現在、主に滑舌についての研究に取り組んでいます。大学生・大学院生を対象とした発話のしにくさの自覚に関するアンケート調査によると、約30%の学生が発話のしにくさを自覚しています。自覚している人の多くは「舌が上手に動かせない」、「滑舌が悪い」、「サ行、ラ行、カ行、タ行の発音が苦手」との回答をしています[1]。
先行研究では、筋萎縮性側索硬化症(ALS)による構音障害のある話者を対象に、舌と下顎の動きと発話明瞭度の関係が調べられてきました。その結果、舌と下顎が同じ方向にしか動かなくなると、発話明瞭度が低下することが報告されています[2]。言い換えると、舌と下顎を別々に動かす能力が保たれていることが、明瞭な発話の維持に重要であることが示されています。
しかし、こうした研究は主に病気や障害のある話者を対象としており、健常者の中での発話明瞭度の個人差と舌・下顎の動きの関係については、これまでほとんど検討されていませんでした。そこで本研究では、発話のしにくさを自覚しており主観的な発話明瞭度が低い話者と、自覚しておらず主観的にも発話明瞭度が高い話者が朗読した時の調音運動を予備的に比較検討しています。
舌運動の観察には磁気センサシステムWave[3,4]を使用します。舌上に3つのセンサ(T1、T2、T3)と下顎(LI)に設置し、イソップ童話の「北風と太陽」(7文、342音素)を本人にとって普通の速さで朗読してもらいました。
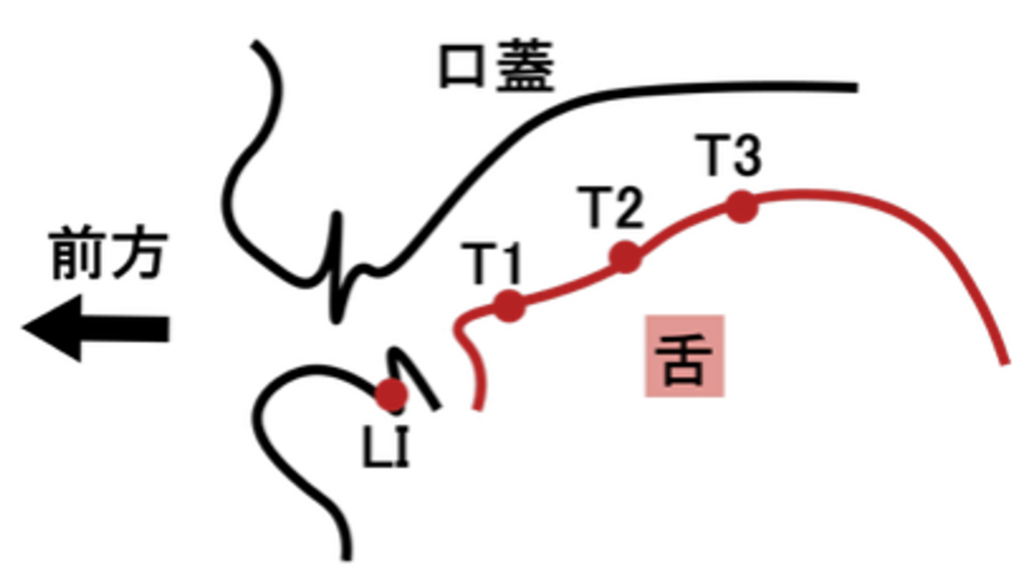
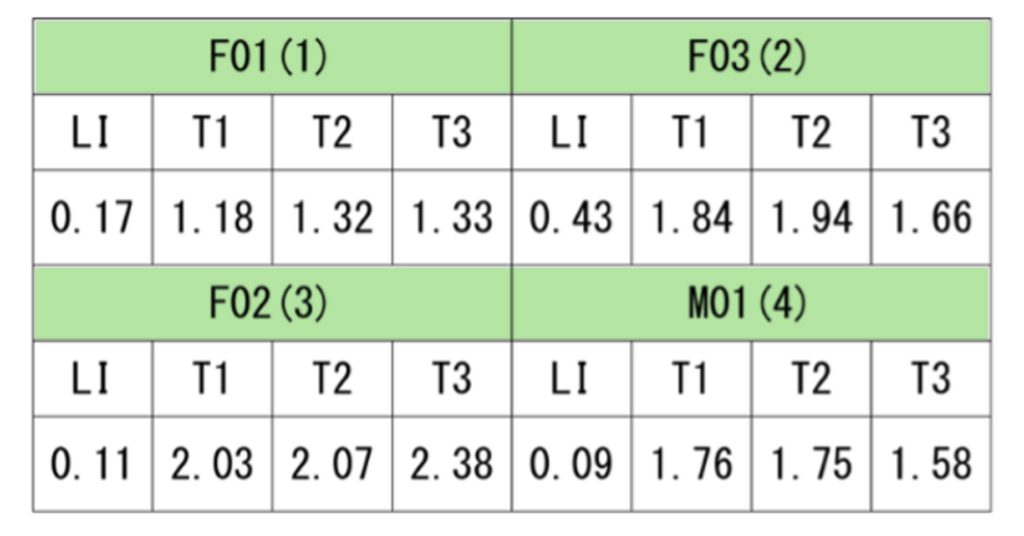
まず、話者ごとに各センサの軌跡を正中矢状断面へ正射影し、その外側を囲む凸包領域を可視化して、凸包面積を正規化して算出しました。発話明瞭度などの主観評価のスコアが高かったF01 とF03 は、スコアの低かったF02 とM01 に比べてLI の凸包面積が大きい傾向が見られました。これは、主観評価の高い話者では下顎を大きく動かしていることを示唆します。
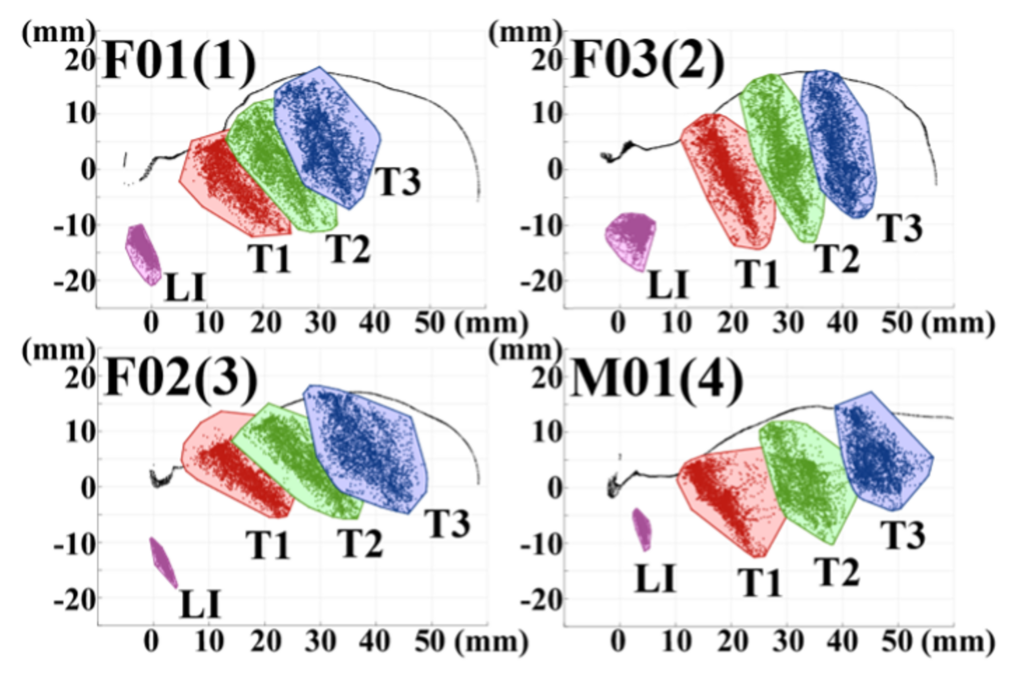
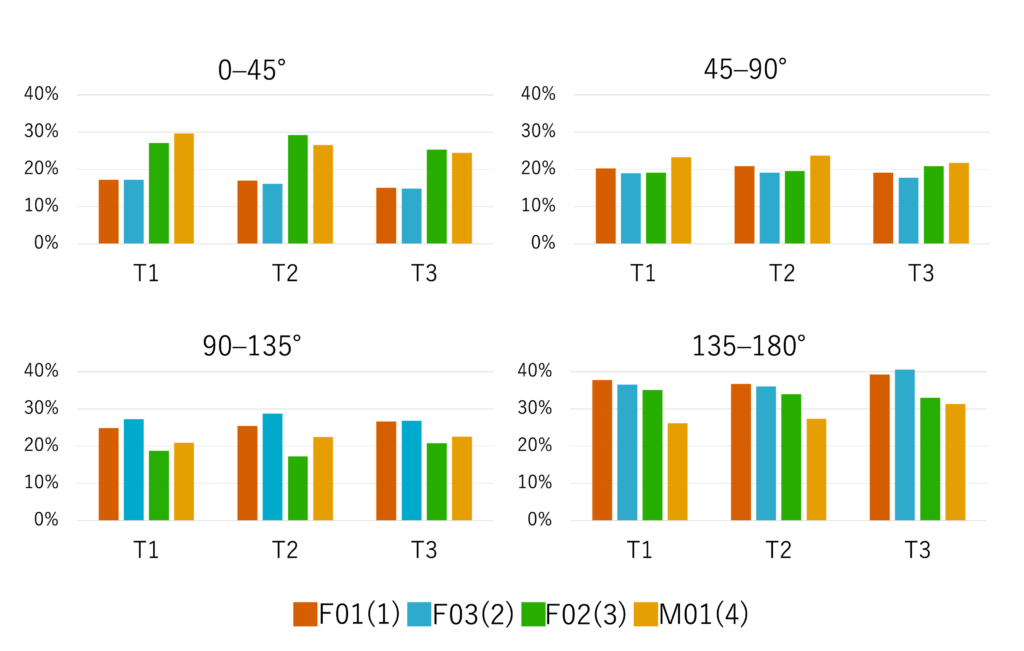
次に、T1とLI、T2とLI、T3とLIのなす角θを4つの区間(0–45°、45–90°、90–135°、135–180°)に分類し、その分布の比率を算出しました。0–45°の比率は、発話明瞭度などの主観評価のスコアが高かったF01とF03では15%前後と低く、スコアが低かったF02とM01では27%前後と高い結果となりました。これは、スコアが高かった話者では、下顎の移動方向と舌の移動方向が独立する傾向が高いことを示唆します。
今後の課題の一つとして、下顎を大きく動かすことが舌の運動に与える影響などについて追究する必要があります。また、竹本研究室では、滑舌の研究以外にもWaveを用いた言い間違いに関する研究にも今後取り組んでいく予定です。
- 北村ら, “大学生・大学院生を対象とした発話のしにくさの自覚に関するアンケート調査,” 日本音響学会誌, 75巻, 3号, pp. 118-124, 2019.
- Rong & Green, “Predicting Speech Intelligibility Based on Spatial Tongue–Jaw Coupling in Persons With Amyotrophic Lateral Sclerosis: The Impact of Tongue Weakness and Jaw Adaptation,” Journal of Speech, Language, and Hearing Research, Vol. 62, No. 8S, pp. 3085-3103, 2019.
- 北村達也, “磁気センサシステムによる調音運動のリアルタイム観測,” 日本音響学会誌, 71巻, 10号, pp. 526-531, 2015)
- Nota et al., “Mapping palatal shape to electromagnetic articulography data: An approach using 3D scanning and sensor matching ,” JASA Express Lett, Vol. 4, No. 1, 015201, 2024.
ポップアウトボイス生成のメカニズムに関する検討
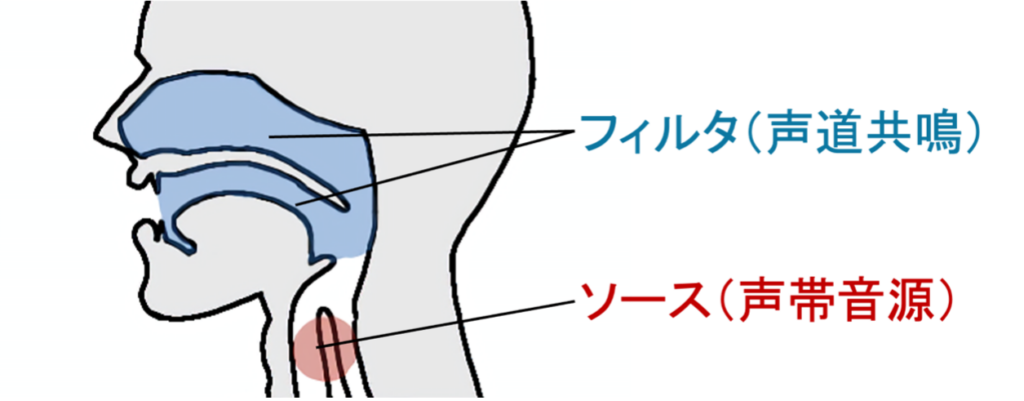
背景雑音などの妨害音がある環境下でも、聞き取りやすい音声をポップアウトボイスと呼びます[1]。ポップアウトボイスは単に音圧レベルが高い音声ではなく、同じ音圧レベルでも際立って知覚されるという特徴があります。先行研究より、ポップアウトボイスは全体的な音の強さ、高周波領域の音の強さ、基本周波数、スペクトルの動的特徴、高周波領域のスペクトル形状など複数の音響的特徴と関係あることが報告されています[2]。しかし、生成のメカニズムについては明らかになっていません。人間の音声は、声帯音源(ソース)に声道共鳴(フィルタ)で音色が付与されることで生成されます。そこで私たちは、生成要因をソース側とフィルタ側のそれぞれから検討してきました。
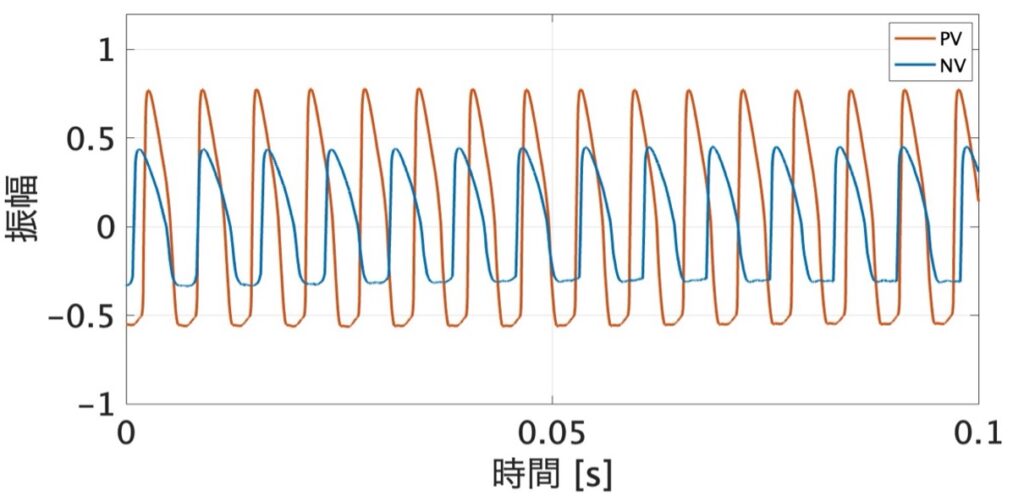
ソース側では、声門の開閉パタンを間接的に観測することができる、Electro Glotto Graphy(EGG)を用いて実験を行いました。「あ」、「い」、「う」などの単母音を実験参加者にとって通る声(PV)と通らない声(NV)で発声した際のEGG波形を記録し、声の高さを示す基本周波数と、声帯の振動周期のゆらぎを表す指標であるjitterを比較検討しました。その結果、基本周波数には有意差が見られませんでしたが、jitterはPVの方が有意に小さい傾向が見られました(t検定,p < 0.05)。この結果から、PVでは声帯の振動周期が安定し、倍音成分が高域まで現れることで発話明瞭度を向上させている可能性が考えられました。また、PVの声帯振動が大きな声を発声する際の特徴と一致していたことから、PVは小さな声でも大きな声と同様の声帯振動を持つ可能性が示唆されました[3]。
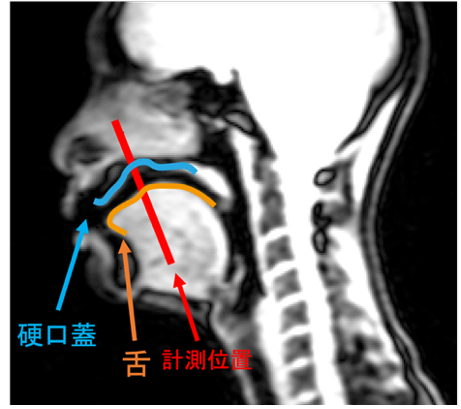
フィルタ側では、PVとNVで同一の文章を読み上げた際の調音運動(舌や軟口蓋などフィルタ側の運動)をリアルタイムMRIと呼ばれる、発話中の声道形状などを動画として記録することができる機械を用いて撮像しました。そしてそのデータをカイモグラフと呼ばれる、任意の線上における部位の変位量を示すことができる方法で分析し、調音運動の差について検討しました。また音声からスペクトルを算出し、口の開きを示す第1フォルマントと、舌の前後位置を示す第2フォルマントを用いて母音空間を分析しました。カイモグラフの分析では、PVでは全体として調音の動きが大きい様子がみられました。母音でみると後舌母音である/a/、/o/ではPVで口腔の容積が増大し、それ以外の/i/、/u/、/e/では減少しており、過剰に調音運動を行っている傾向がみられました。
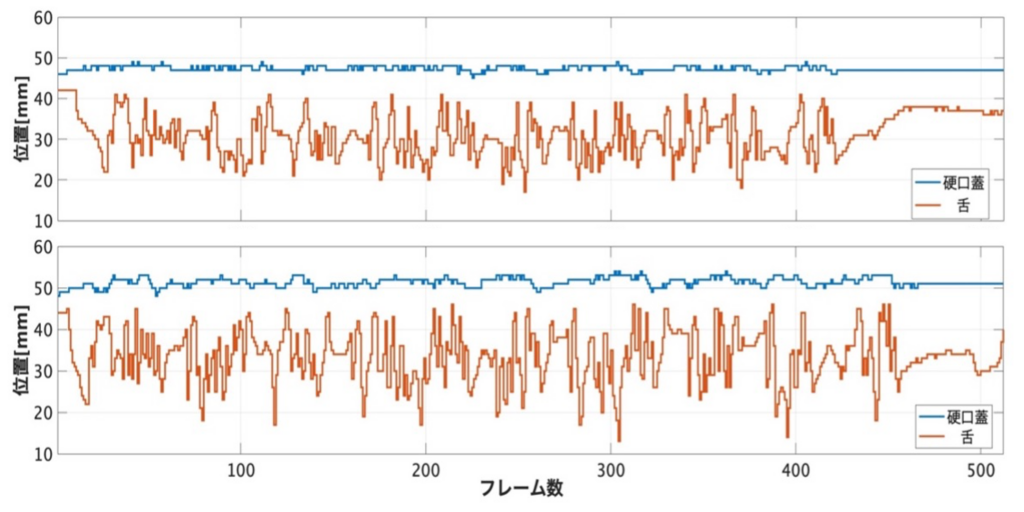
(上: PV、下: NV)
母音空間の分析では、すべての実験参加者においてNVよりPVで母音空間が大きいことが確認され、ポップアウトボイスは過剰な調音運動により母音空間を拡大させることで明瞭度を向上させている可能性が示されました[5]。
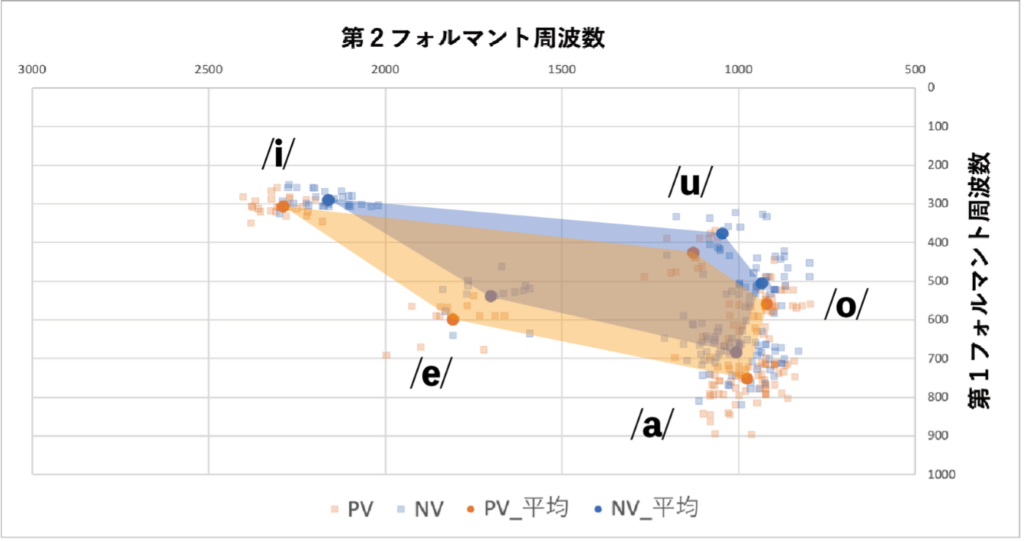
- 北原ら,”様々なSN比におけるポップアウトボイスの検出”,音講論集,pp.1049-1052, 2022.9.
- Amano et al., “Acoustic features of pop-out voice in babble noise”, Acoust. Sci. Tech., Vol. 43, No. 2, pp. 105-112, 2022.
- Ternström et al., “Effects of the Lung Volume on the Electroglottographic Waveform in Trained Female Singers”, J. Voice, Vol. 34, No. 3, pp. 485.e1-485.e21, 2020.
- Han et al., “Fundamental frequency range and other acoustic factors that might contribute to the clear-speech benefit”, J. Acoust. Soc. Am., Vol. 149, No. 3, pp. 1685–1698, 2021.
